Overview Tab
Overview Tab
#38xxx
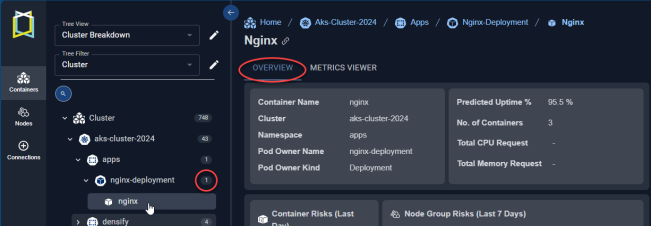
The blocks on this tab provide a visual overview of a single container. When navigating the tree viewer, you will see this tab when a single item is selected and the Summary tab when more than one container is selected.
Figure: Locating the Overview Tab
You will also see a popup of this page when you click the hyperlink in the AI Analysis Details tab.
You also have access to the metrics viewer when a single container is selected.
Figure: Overview Tab
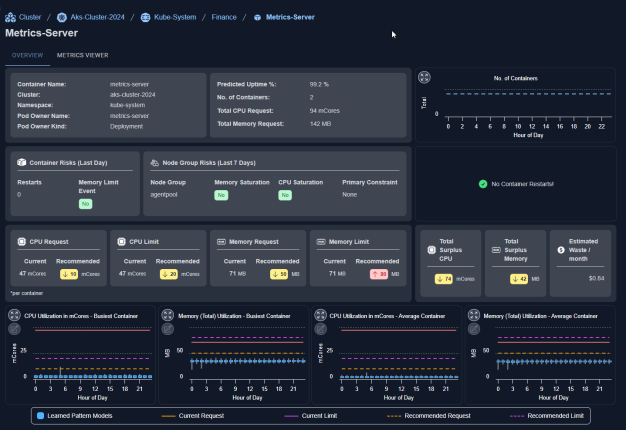
Summary Block
Identifying details and key metrics are displayed in a block at the top of the page.
Figure: Summary Block

|
Component/Column Name |
Description |
|---|---|
|
Container Name |
The name of the container. |
|
Cluster |
The parent cluster containing this container |
|
Namespace |
The namespace associated with the container. |
|
Pod Owner Name |
This is the name of the controller or pod. You can have one or more containers per pod. |
|
Pod Owner Kind |
The controller type that monitors and maintains the state of your cluster. This can be one of DaemonSet, Deployment, ReplicaSet, ReplicationController, StatefulSet, etc. |
|
Predicted Uptime % |
Uptime % is the total time the container has been running as a percentage of the total hours since the container was deployed. (Running Hrs/Total Hrs) When using pay-per-use pricing models, the amount of time each instance has been running, is required to accurately estimate future costs. The predicted uptime (%) for a cloud instance or container, is based on the percentage of hours CPU utilization data is present in the historical interval, as specified in the policy settings for the entity. For Auto Scaling groups and VM Scale Sets and Individual child instances are not taken into account. Predicted uptime %, for new instances or containers, that started mid-way through the historical interval, is calculated from the time/date that the instance was started as opposed to the beginning of the interval, resulting in more accurate predictions for future usage. For example, the uptime is the number of hours that have "CPU Utilization in mcores", and the range is the lesser of when the container was discovered, or the range defined in the policy. Looking at a specific container that was discovered on Jan 5th 2024, that has workload of 42 hours since that date, then the uptime % is 42 hrs/(13 days x 24 hrs/day) = 13.4%. This is the value shown in this column. |
|
No. of Containers |
This is the current number of containers running in the selected cluster/namespace/pod combination. |
|
Total CPU Request (mCores) |
This is the total CPU request value for the container and is calculated as (current value * No. of Containers). For containers where the current CPU value is unspecified '0' is displayed in this column. |
|
Total Memory Request (MB) |
This is the total memory request value for the container and is calculated as (current value * No. of Containers). For containers where the current CPU value is unspecified "0" is displayed in this column. |
|
No of Containers |
This charts shows the number of containers that were running during each hour. All other charts are available on the Metrics Viewer Tab tab. |
The cost per core and per GB of memory is configurable. Contact [email protected] for details.
Risk Summary
These 2 blocks summarize potential resource risks for the container and node group, on which the containers are running.
Figure: Risk Summary Blocks

|
Column/Chart Name |
Description |
|---|---|
|
Container Risks (Last Day) |
|
|
Restarts |
The total number of restarts of all containers associated with the deployment, in the last day. A dash (-) is displayed if no data has been collected. |
|
Memory Limit Event |
Indicates if the peak working set memory utilization was near or exceeded the memory limit, in the last 7 days. The table cell is shaded to clearly indicate this container is at risk. A value of "No" indicates:
|
|
Node Group Risks (Last 7 Days) |
|
|
Node Group |
The name of any node groups contained in this cluster. If the cluster contains multiple node groups, all node groups are listed. For nodes that do not belong to a node group, the node group value will be <cluster-name>-default”. |
|
Memory Saturation |
Indicates whether or not memory utilization is above the saturation threshold, during the past 7 days of history. The saturation threshold value is configurable. Contact [email protected] for details. |
|
CPU Saturation |
Indicates whether or not CPU utilization is above the saturation threshold, during the past 7 days of history. The saturation threshold value is configurable. Contact [email protected] for details. |
|
Primary Constraint |
Indicates the reason that more containers cannot be added to this node group. The following values are evaluated and whichever has the largest value is identified as the primary constraint:
|
|
No Container Restarts |
This charts shows the number of container restarts that occurred during each hour. A message indicates if there were no restarts. All other charts are available on the Metrics Viewer Tab tab. |
Resource Allocation Recommendations
This block summarizes the current and recommended resource allocations for the selected container.
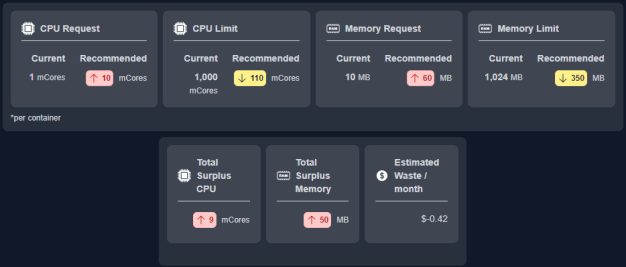
|
Column Name |
Description |
|---|---|
|
CPU Request (mCores) Memory Request (MB) CPU Limit (mCores) Memory Limit (MB) |
The current request and limit CPU | memory values for the selected container are displayed in these 4 blocks. For containers where the current CPU value is unspecified a dash (-) is displayed in the main table and '0' is displayed in the "Total" row. |
|
Recom. CPU Request (mCores) Recom. Memory Request (MB) Recom. CPU Limit (mCores) Recom. Memory Limit (MB) |
The recommended request and limit CPU | memory values for this container are displayed in these blocks. |
|
Total CPU Request (mCores) |
This is the total CPU request value for the container and is calculated as (current value * No. of Containers). For containers where the current CPU value is unspecified '0' is displayed in this column. |
|
Total Surplus CPU Request (mCores) |
This is the total surplus CPU request value for the container and is calculated as (current value * No. of Containers). For containers where the current CPU value is unspecified "0" is displayed in this column. |
|
Estimated Waste/month |
If the recommendations are implemented, the total savings or waste per container are indicated here. This value is calculated as the total savings/number of containers. Calculated as: (Surplus CPU_Req * CPU_price) + (Surplus Mem_Req * Mem_Price) When calculating costs the Recommended CPU | Recommended Memory Request values are used for containers that have no request values specified. |
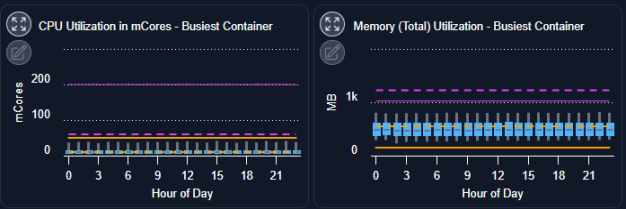
Workload Charts
The last section provides 4 workload charts that show hourly min/max and sustained activity for the selected system. The charts show the current and the recommended settings for selected workloads. See AI Analysis Details Charts for details on using these charts to review workload data.
- CPU Utilization in mCores - Busiest Container
- CPU Utilization in mCores - Average Container
- Memory (Total) Utilization - Busiest Container
- Memory (Total) Utilization - Average Container
All other metrics are available on the Metrics Viewer Tab tab. You can also expand any chart to the modal view and select other metrics for review.
Figure: Workload Charts